
杰奇CMS小说 关关采集器规则编写教程 船说小说CMS采集规则
正则通用替代符
\d* 不需要的数字
(\d*) 需要的数字
\d+ 不需要的数字 (和上面的第一个功能一样,写法不同而已)
(\d+) 需要的数字 (和上面的第二个功能一样,写法不同而已)
.+? 不需要的字符
(.+?) 需要的字符
\s* 空格或换行
((.|\n)*) 章节内容截取
{NovelKey} 表示小说编号
{NovelKey/1000} 表示小说编号除以1000 因为我们经常看到/44/44710/之类的
{ChapterKey} 表示章节ID
{NovelPubKey} 表示目录页地址
规则编写
以下为教程图文供参考,如无特殊说明的选项,默认跳过不设置
RuleVersion规则版本:就是自己的一个规则的备注版本(随便写)
RuleID规则编号:自己备注的编号 (随便写)
GetSiteName站点名称:采集网站的名称
GetSiteCharset站点编码:采集的源站的编码是UTF8或者GBK
GetSiteUrl站点地址:采集网站的地址
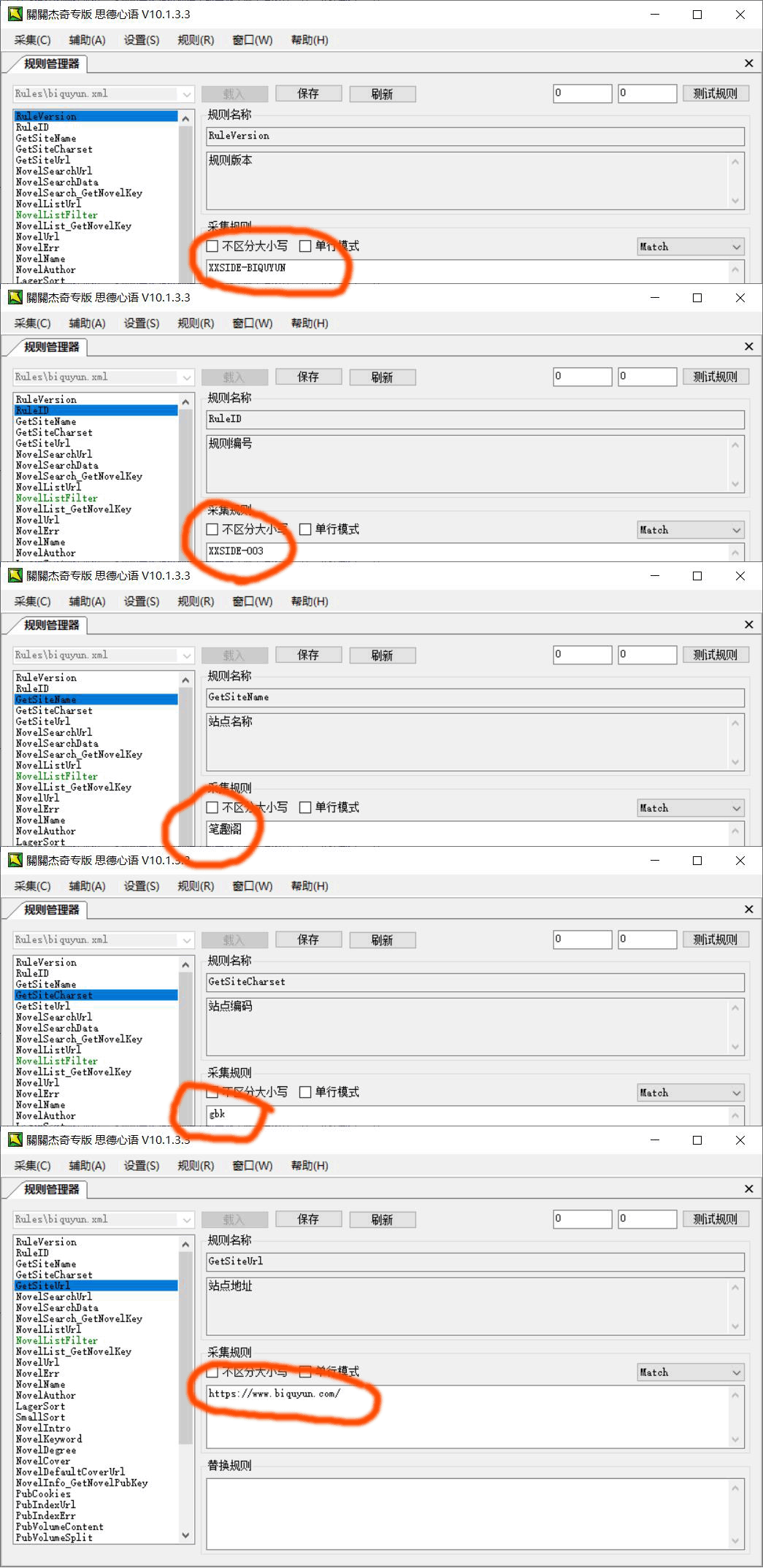
NovelListUrl站点最新列表地址:需要获得小说列表的地址
这里教程采集的列表页是:笔趣阁的网址,如图所示
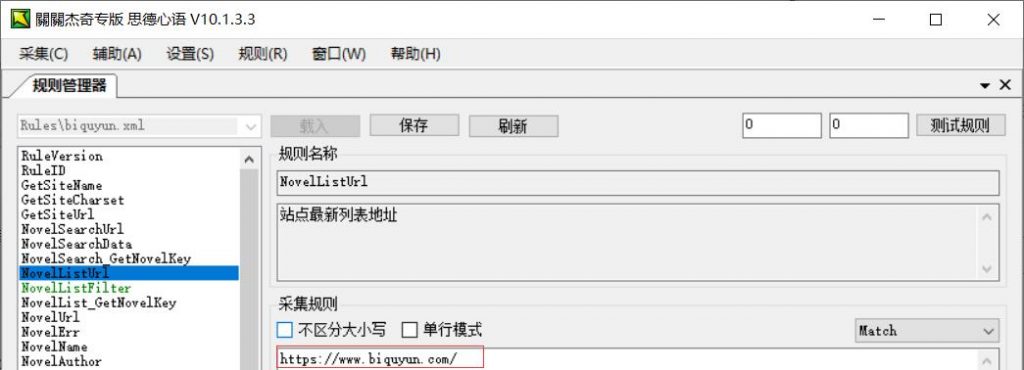
NovelList_GetNovelKey从最新列表中获得小说编号:此规则中可以同时获得书名以方便手动时查看,获得结果存入{NovelKey}变量
这个就是获取小说ID和小说名,打开笔趣阁,右键查看源代码,找到最新更新列表,看到有小说ID和小说名的这一段内容,我们需要的就是这段内容,记住获取的这段代码必须包含小说ID和小说名,并且要是唯一的,关关编写规则要点就是选择的代码必须是统一且必须是唯一的,如果不是唯一的就会获取到多个值。

那我们关关中该如何处理这段代码,看图,其中10344这个就是小说的唯一ID,所以我们需要,所以使用(\d*),而10我们则不需要所以就使用\d*,小说名: 仙师无敌 是我们需要的所以我们要使用(.+?),就变成了如下图所示:
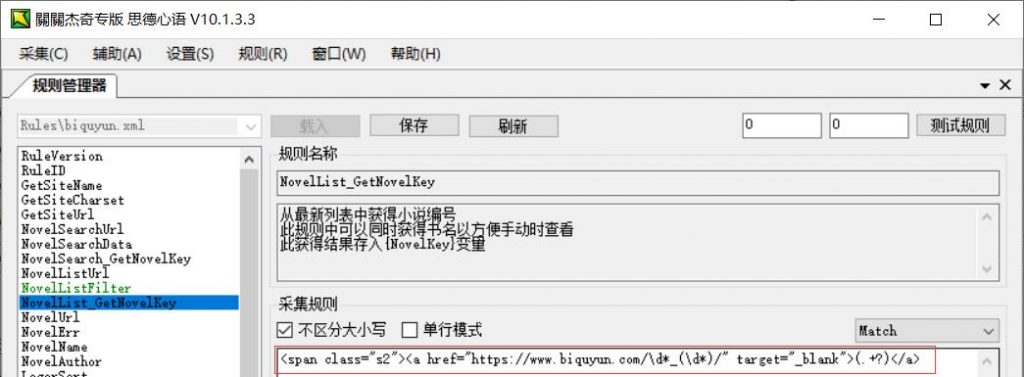
NovelUrl小说信息页地址:可调用{NovelKey}变量,{NovelKey}一般情况表示小说编号
一般笔趣阁模版的信息页和目录页在一个页面,所以直接填就行了。比如我们随便用一个https://www.biquyun.com/10_10344/,这种就应该改成https://www.biquyun.com/{NovelKey/1000}_{NovelKey}/,其中{NovelKey}在上面说了代表小说的意思。
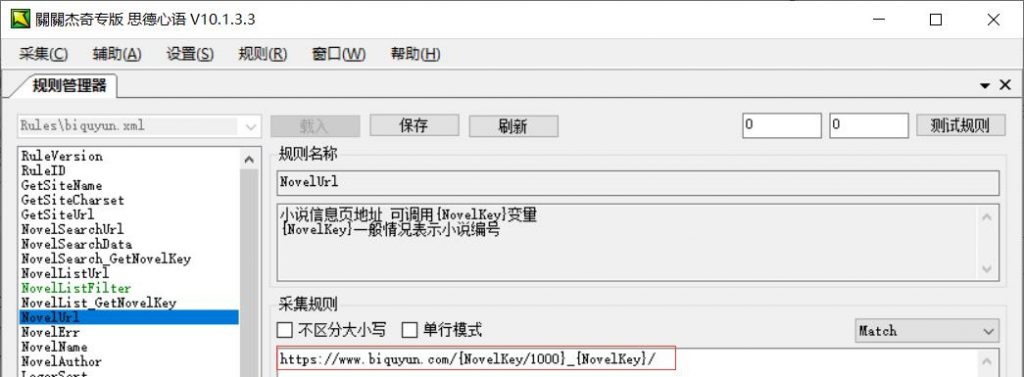
这些都搞定了我们就要开始在 https://www.biquyun.com/10_10344/ 页面中(右键》》查看源码)获取小说的名字 作者 状态 封面这些了。
NovelName获得小说名称正则:获取小说名称
NovelAuthor获得小说作者正则
LagerSort获得小说大类正则
SmallSort获得小说小类正则
NovelIntro获得小说简介正则
NovelKeyword获得小说主角(关键字)正则
NovelDegree获得写作进程正则(请把全本小说替换成完成、完结、完本)
NovelCover获得小说封面正则
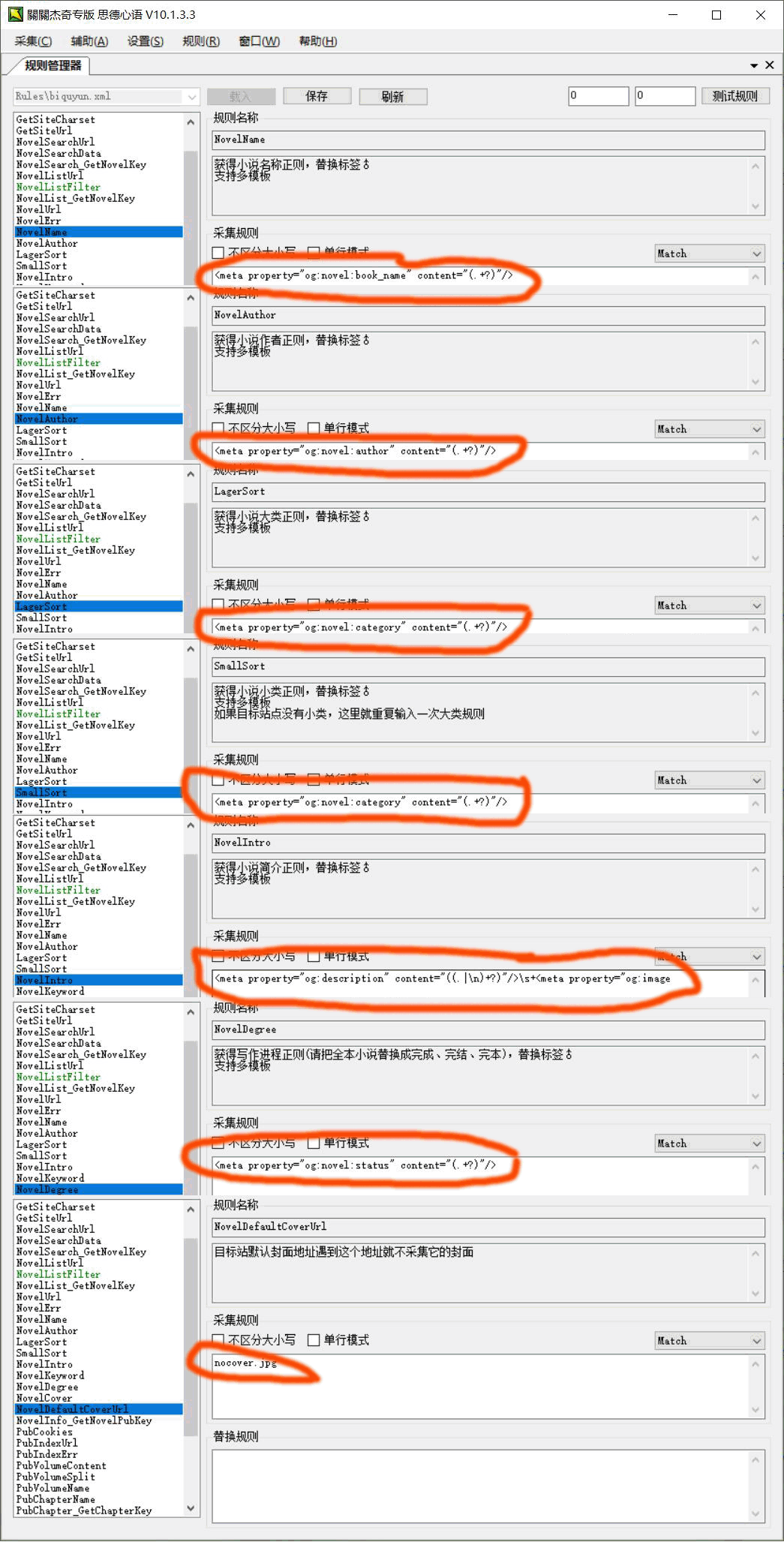
1.如果有360结构化:这里要特别说明一下有个简单的方法获取到这些值,这就得感谢360结构化了,把一切就简单化了。下图中就是所谓的360结构化,你写规则的时候首先就要去找这个东西,一般在信息页或者目录页,甚至在手机版中,如果有那么就简单多了,如果没有那就麻烦一些。现在的小说站基本都会有有这些信息的,如果没有找到或者没有,直接跳过,看第二点没有360结构化的情况。

- 下面我们通过360结构化来编写下面的采集正则,我会提供大家示例,大家根据上图寻找对应编写。
- NovelName:og:title” content=”(.?)”
- NovelAuthor:novel:author” content=”(.?)”
- LagerSort:novel:category” content=”(.?)”
- SmallSort:novel:category” content=”(.?)”
- NovelIntro:og:description” content=”(.?)”/>
- 小说简介如果(.?)获取不了就改成((.|\n)?)
- NovelKeyword:og:title” content=”(.?)”
- NovelDegree:og:novel:status” content=”(.?)”
- NovelCover:og:image” content=”(.?)”\s*<meta property=”og:novel:category”
- 为什么获取封面要这么写,实测过如果没有封面会获取到另一个值,甚至是对方的网址,这不是我们希望看到的。
- NovelDefaultCoverUrl:一般填写nocover.jpg或者noimg.gif,大多数为nocover.jpg,基本没有第三种。
- NovelInfo_GetNovelPubKey:novel:read_url” content=”(.*?)”
- 以上就是示例,大家可以参考上图进行查找修改,下图就是我们查找修改后在关关填写的信息,图片太大了,我的1M带宽不够了,所以大家点击图片稍等会出现大图。
2.如果没有360结构化: 如果没有360结构化的我们该怎么写,其实也很简单就是找相关信息而已,就是麻烦一些。 还是在 https://www.biquyun.com/10_10344/ 页面中(右键》》查看源码) 获取信息。

这里就不多说了,直接给示例,大家参考对比就可以,如果还是不懂可以在下方留言,千万记住唯一性很重要。

好了,基本这个代码就讲到这里,我建议你先不要问人,自己写一遍,就知道为啥要这么写了。下面我们继续
PubIndexUrl:如果信息页和目录页是一个可以直接填写{NovelPubKey},如果不一样就像写NovelUrl一样写目录页地址就行了

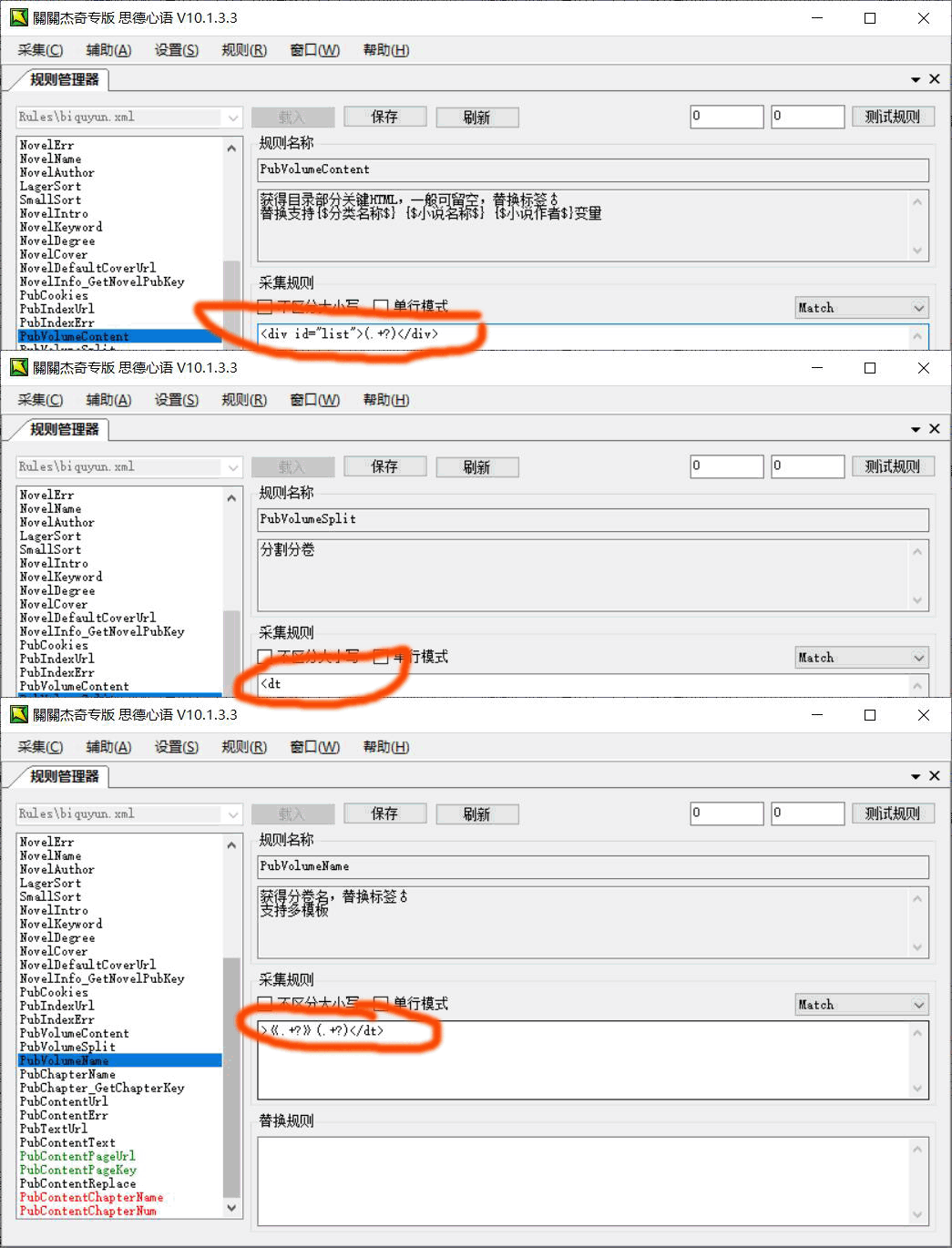
PubVolumeContent获得目录部分关键HTML,一般可留空
PubVolumeSplit分割分卷
PubVolumeName获得分卷名
一般这三个可以留空,但是有的站点为避免采集会设置干扰,这里我们用目标站讲解一下。
这三个参数的目的是排除列表页面中可能存在其他干扰因素和导致唯一性不确定。
例如:一个页面中有更新列表,也有章节列表,这样会导致页面最后统计的章节数最后超过实际的章节数。如下图,本身只有1113个章节,可是采集的时候会把上面的最新章节算进去,变成1121个章节,这样导致目录数据不对,采集失败。
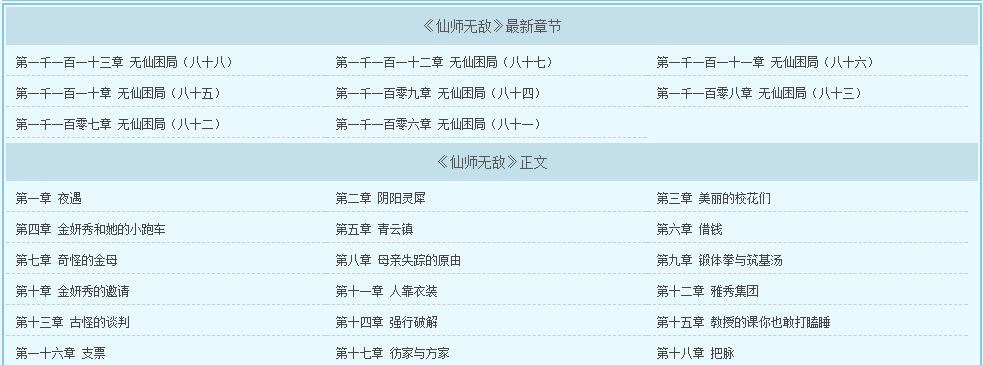
所以我们这里设置如下图,大家对比参考,不做详细介绍。
PubChapterName获得章节名
PubChapter_GetChapterKey获得章节地址(章节编号)

PubChapterName直接按照下图写就行了,因为a href中的值是不需要的直接过滤就行了
PubChapter_GetChapterKey就要也按照下图写,因为9323884这个是我们需要的章节ID,所以要用(\d*)

PubContentText获得章节内容的正则:最后要写的就是PubContentText这个了,也就是获取章节内容,同样打开章节页面右键源代码,找到章节内容
选取
结尾,写成
就行了,基本上笔趣阁模版的源站都这样。 这里因为我们的目标源站设置了仿采集,导致唯一性不足,所以我们这样写,大家对比查看。

所有的采集规则编写完毕,我们先测试一下,会看到成功了。激动不!敢不敢动?如果没有成功回头排查原因。

大家先不要激动,还有一个非常重要的,我们要继续设置,是不是很累,我比你们都累啊… 那就是去广告了,在替换规则中填入你想要去掉的广告,一行一个或者用|分割掉,如果你想替换就这样写 笔趣阁♂思德心语,替换标识符为♂,这样笔趣阁这三个字就变成思德心语了 。去广告主要针对NovelIntro获得小说简介正则和PubContentText获得章节内容的正则。

去广告不需要什么技术,只要多找就行了,如果你遇到这种一段话的,比如:思德心语小说网 www.side.com ,最快更新大红娘最新章节!直接写成: 思德心语小说 网.+?最新章节!就行了,没必要分割一个个去掉。
最后测试规则就行了,一个基本的规则就这样写,很简单多玩一下就懂了。
其他问题
1.有时候我们采集链接时,id不是数字,而是拼音
编写采集的时候只需要把(\d*)换成(.+?)就行了
2.采集的章节是分页的,采集不全
编写采集的时候只需要寻找他的手机端章节链接,查看是否不是分页的,一般手机端不是分页形式,所以我们采集页面链接换成手机链接采集。
3.采集的最新章节显示“正在手打中”
这个我们只需要在采集的时候,编辑不采集最新的倒数X个章节或者少于X字节的文章(X你自己可以设置)
4.采集不到最新章节
因为他在章节列表页面的最新章节那里,一般会加一个class参数防止采集,用替换代替即可解决
其他问题收集中…欢迎大家反馈
版权与免责声明:
凡注明稿件来源的内容均为转载稿或由网友用户注册发布,本网转载出于传递更多信息的目的;如转载稿涉及版权问题,请作者联系我们,同时对于用户评论等信息,本网并不意味着赞同其观点或证实其内容的真实性;
![英雄棋士团(预下载)?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/shouyoupic/yingxiongqishituanyuxiazai.jpg)
![美食小当家?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/shouyoupic/meishixiaodangjia.png)
![2047?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/shouyoupic/2047.jpg)
![荣誉指挥官(预下载)?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/shouyoupic/rongyuzhihuiguanyuxiazai.png)
![繁荣美食市场物语?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/shouyoupic/fanrongmeishishichangwuyu.jpg)
![夸克浏览器 v4.2.1.138 好用的手机浏览器?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/appimg/202007/kuakezuolanqi.jpg)
![移动办公软件 OfficeSuite Premium v10.18.28716 内购解锁版?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/appimg/202007/yidongbangongruanjian.jpg)
![乐秀视频编辑器 VideoShow v8.8.4 内购解锁版?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/appimg/202007/lexiushipinbianjiqi.png)
![X 浏览器 v3.3.9 一款小巧的安卓浏览器?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/appimg/202007/x.jpg)
![安卓密码管理软件 Enpass v6.4.5.368 内购解锁版?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/appimg/202007/anzhuomimaguanliruanjian.jpg)
![差分复制同步 FastCopy-M v3.6.3.51 绿色便携版?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/softimg/FastCopy3.png)
![多标签页拓展 Clover v3.5.2 Build 19809 精简绿色版?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/softimg/Clover.png)
![文件重命名 Advanced Renamer v3.85 Lite 绿色便携版?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/softimg/Advanced_Renamer.png)
![网络防火监控 GlassWire Elite v2.1.166 绿色便携版?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/softimg/GlassWire.png)
![影音播放器 Daum Potplayer v1.7.20538 美化便携版?=$bqr['banben']?>](http://shouyouimg.cnzzla.com/d/file/softimg/PotPlayer.png)